
Note: This is the fixed version of my previous post
http://www.mycpu.org/set-or-unique/. If you are interested in what needed fixing
I recommend you go there first.
Problem:
To find unique elements in a vector quickly with existing std:: routines.
Setup Code:
CMake
So I setup a quick Google Benchmark harness:
cmake_minimum_required(VERSION 3.16)
# Compiler and Standard
set(CMAKE_C_STANDARD 99)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_C_COMPILER clang-8)
set(CMAKE_CXX_COMPILER clang++-8)
# set the project name
set(this_project project_name)
# RUST, Erlang, what else
project(${this_project} C CXX)
add_subdirectory(src)
find_package(benchmark REQUIRED)
target_link_libraries(${this_project} benchmark::benchmark)
set(CMAKE_BUILD_TYPE Release)
set(CMAKE_ENABLE_EXPORTS ON)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
Measure the Truth
Get a few (1000) random numbers
std::vector<int> nums_;
auto helper_(int n) -> std::vector<int> {
auto gen_node_ = [=]() -> int { return rand() % 100; };
while (n--) { nums_.emplace_back(gen_node_()); }
return nums_;
}
Clean up after yourself
nums_.clear();
Candidate Solutions:
std::set
static void BM_Set(benchmark::State& state) {
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_.emplace_back(gen_node_()); }
auto start = std::chrono::high_resolution_clock::now();
std::set<int> s;
for (const auto& e_ : nums_) { s.insert(e_); }
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_.clear();
}
}
BENCHMARK(BM_Set);
std::unordered_set
static void BM_UnorderedSet(benchmark::State& state) {
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_.emplace_back(gen_node_()); }
auto start = std::chrono::high_resolution_clock::now();
std::unordered_set<int> s;
for (const auto& e_ : nums_) { s.insert(e_); }
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_.clear();
}
}
BENCHMARK(BM_UnorderedSet);
std::sort and std::unique
Apparently, std::unique simply swaps duplicate numbers to the end of the
array as it processes elements. One Possible Impl of std::unique() is:
template <class ForwardIterator>
ForwardIterator unique (ForwardIterator first, ForwardIterator last)
{
if (first==last) return last;
ForwardIterator result = first;
while (++first != last)
{
if (!(*result == *first)) // or: if (!pred(*result,*first)) for version (2)
*(++result)=*first;
}
return ++result;
}
From this snippet, it’s clear that for us to use std::unique() we will need
the input to already be sorted. This is additional work but whatever! So let’s
sort it, and since this is a requirement of the input for this algo to work we
will need to account the time taken to sort the input array as well.
static void BM_UniqueSort(benchmark::State& state) {
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_sorted.emplace_back(gen_node_()); }
auto start = std::chrono::high_resolution_clock::now();
std::sort(nums_sorted.begin(), nums_sorted.end());
auto uniq_iter = std::unique(nums_sorted.begin(), nums_sorted.end());
nums_sorted.erase(uniq_iter, nums_sorted.end());
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_sorted.clear();
}
}
BENCHMARK(BM_UniqueSort);
What If Inputs Are Already Sorted?
std::set on Sorted Inputs
static void BM_SetSortedInput(benchmark::State& state) {
clear_up_();
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_.emplace_back(gen_node_()); }
std::sort(nums_.begin(), nums_.end());
auto start = std::chrono::high_resolution_clock::now();
std::set<int> s;
for (const auto& e_ : nums_) { s.insert(e_); }
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_.clear();
}
}
BENCHMARK(BM_SetSortedInput);
static void BM_UnorderedSetSortedInput(benchmark::State& state) {
clear_up_();
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_.emplace_back(gen_node_()); }
std::sort(nums_.begin(), nums_.end());
auto start = std::chrono::high_resolution_clock::now();
std::unordered_set<int> s;
for (const auto& e_ : nums_) { s.insert(e_); }
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_.clear();
}
}
BENCHMARK(BM_UnorderedSetSortedInput);
static void BM_UniqueSortedInput(benchmark::State& state) {
clear_up_();
for (auto _ : state) {
auto n = 1000;
while (n--) { nums_.emplace_back(gen_node_()); }
std::sort(nums_.begin(), nums_.end());
auto start = std::chrono::high_resolution_clock::now();
auto uniq_iter = std::unique(nums_.begin(), nums_.end());
nums_.erase(uniq_iter, nums_.end());
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(
end - start);
state.SetIterationTime(elapsed_seconds.count());
nums_.clear();
}
}
BENCHMARK(BM_UniqueSortedInput);
Results:
Here are the results:
2021-01-05 23:16:32
Running ./src/practice
Run on (16 X 3700 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 64 KiB (x8)
L2 Unified 512 KiB (x8)
L3 Unified 8192 KiB (x2)
Load Average: 1.74, 1.14, 0.74
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
***WARNING*** Library was built as DEBUG. Timings may be affected.
---------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------
BM_StringCreation 32.4 ns 32.4 ns 21493232
BM_StringCopy 74.6 ns 74.6 ns 9293176
BM_Set 291289 ns 291217 ns 2295
BM_UnorderedSet 138328 ns 138287 ns 5368
BM_UniqueSort 205645 ns 205554 ns 3515
BM_SetSortedInput 413038 ns 412956 ns 1708
BM_UnorderedSetSortedInput 289016 ns 288956 ns 2414
BM_UniqueSortedInput 197036 ns 196992 ns 3446
Benchmark
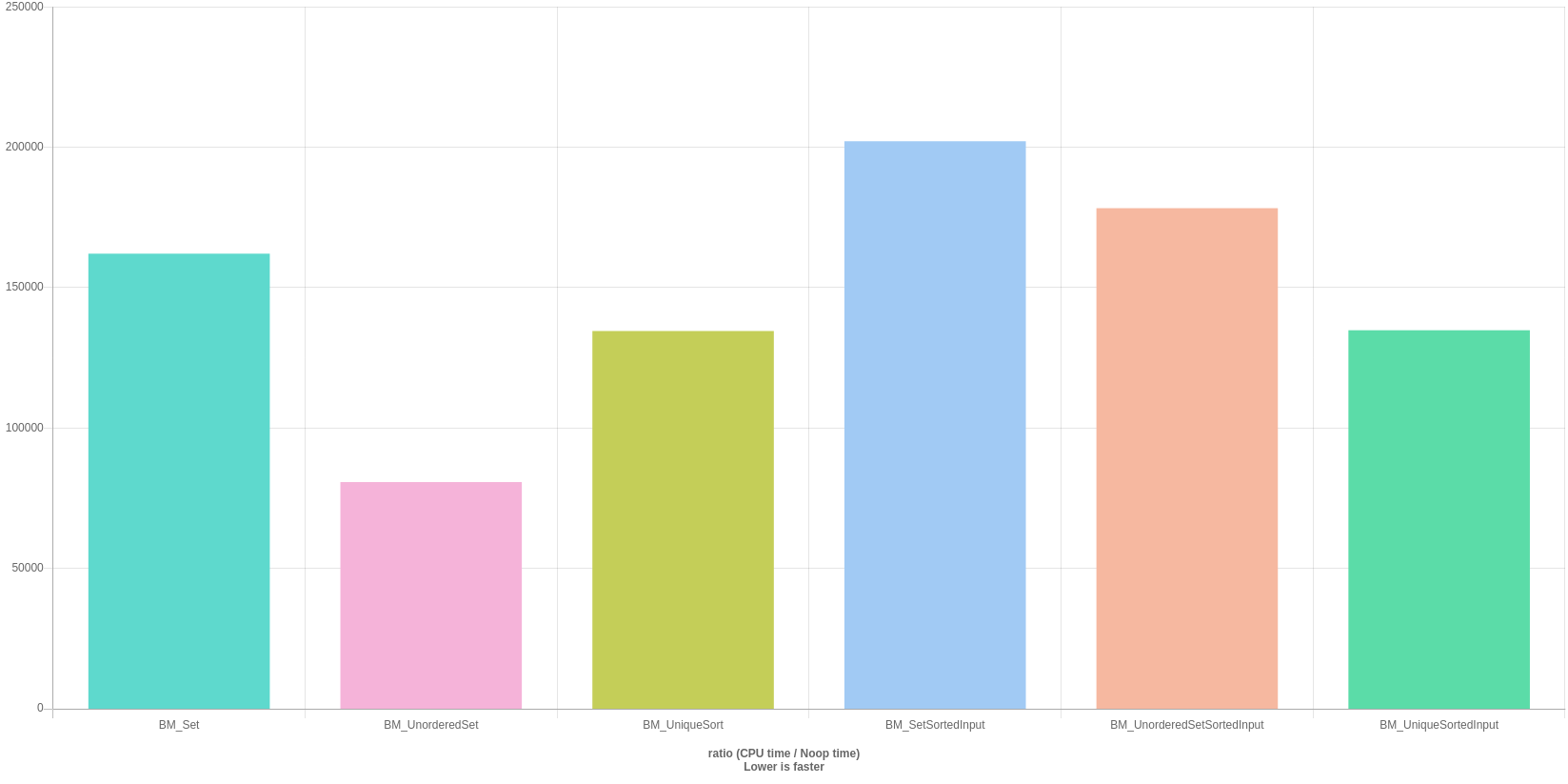
Refer: https://quick-bench.com/q/kq7yeDlz9R6HV-0XE37eRiGINYM
Funny thing is that a std::set and std::unordered_set perform worse on an
already sorted input.
The best bang for buck appears to be from using std::unordered_set on unsorted data!
sudo ~/bin/perf stat -e "sched:sched_process*,task:*,L1-dcache-loads,L1-dcache-load-misses,cycles,cs,faults,migrations" -d -d -d ./src/project_name
<-dcache-loads,L1-dcache-load-misses,cycles,cs,faults,migrations" -d -d -d ./src/project_name
2021-01-05 23:18:41
Running ./src/project_name
Run on (16 X 3700 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 64 KiB (x8)
L2 Unified 512 KiB (x8)
L3 Unified 8192 KiB (x2)
Load Average: 0.62, 0.97, 0.73
---------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------
BM_StringCreation 32.1 ns 32.1 ns 21413542
BM_StringCopy 69.3 ns 69.3 ns 9886036
BM_Set 287445 ns 287279 ns 2395
BM_UnorderedSet 128834 ns 128765 ns 4881
BM_UniqueSort 198459 ns 198352 ns 3642
BM_SetSortedInput 406139 ns 405924 ns 1675
BM_UnorderedSetSortedInput 289739 ns 289561 ns 2444
BM_UniqueSortedInput 193530 ns 193429 ns 3574
Performance counter stats for './src/project_name':
0 sched:sched_process_free
1 sched:sched_process_exit
0 sched:sched_process_wait
0 sched:sched_process_fork
1 sched:sched_process_exec
0 sched:sched_process_hang
0 task:task_newtask
1 task:task_rename
40,684,273,179 L1-dcache-loads (41.65%)
1,721,548 L1-dcache-load-misses # 0.00% of all L1-dcache hits (41.71%)
32,401,365,957 cycles (41.76%)
746 cs
147 faults
2 migrations
40,700,296,235 L1-dcache-loads (41.79%)
1,678,961 L1-dcache-load-misses # 0.00% of all L1-dcache hits (41.79%)
<not supported> LLC-loads
<not supported> LLC-load-misses
4,213,638,640 L1-icache-loads (41.71%)
1,964,508 L1-icache-load-misses # 0.05% of all L1-icache hits (41.66%)
236,237 dTLB-loads (41.61%)
82,233 dTLB-load-misses # 34.81% of all dTLB cache hits (41.58%)
37,522 iTLB-loads (41.58%)
7,523 iTLB-load-misses # 20.05% of all iTLB cache hits (41.58%)
575,582 L1-dcache-prefetches (41.58%)
<not supported> L1-dcache-prefetch-misses
7.665853273 seconds time elapsed
7.644790000 seconds user
0.000000000 seconds sys
My Podcast!
If you like topics such as this then please consider subscribing to my podcast. I talk to some of the stalwarts in tech and ask them what their favorite productivity hacks are:
Available on iTunes Podcast
Visit Void Star Podcast’s page on iTunes Podcast Portal. Please Click ‘Subscribe’, leave a comment.
