
A typical Deep Learning Workflow from a software engineering design perspective is shown in the figure below. This is a very high level overview of how a typical process flow works. There are exceptions to this when using Unsupervised Learning Techniques, but we will ignore them for sake of simplicity.

In production systems, the most amount of time and compute resources are spent
in the iteration of Input -> Model -> Output cycle. It’s the bottom row in
the figure. If you think about relatively mature models that perform
off-the-shelf techniques, ex: Object Detection, Image Classification, Text
Classification etc this is truer than other cases. Common Sense follows that it
is imperative that this control path be the focus of all optimizations. It’s the
reason behind AWS launching a completely separate service called SageMaker
Neo. To be fair, optimal inference is
just one of the many aspects/features of this service. Check it out.
TVM is an open source project that aims to
standardize the representation of output from the Training phase of the
several Deep Learning Frameworks and optimize for the supported target hardwares
(plenty of them). TVM does this by optimizing the implementation of the
individual operators in the standardized representation for each supported
hardware architecture.
So far it’s all sunshine and roses, correct? The trouble is when you smell
them. They stink! A harsh reality is that most of the efforts were (rightly)
spent into achieving a stage where requests can be sent continuously to make
inferences. But these inferences were simply put behind a Flask
App which is the
equivalent of having a single Raspberry Pi powered server to handle all the
search requests of Google (exaggerated but true).
So many big players have put out significant efforts to solve this issue using their know-how. As a result, there are several acceptable solutions being used in production by several players:
To give you a bird’s view here’s the MXNet Solution from the AWS Blog
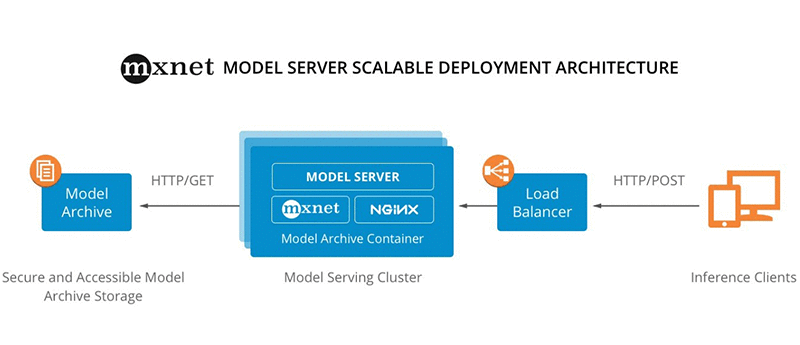
Start the Server:
Looking at the documentation, it is pretty easy to get started.
mxnet-model-server --models squeezenet=https://s3.amazonaws.com/model-server/models/squeezenet_v1.1/squeezenet_v1.1.model
Request from Client:
Now the client can send HTTP requests to obtain inferences
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl http://127.0.0.1:8080/squeezenet/predict -F "input0=@kitten.jpg"
Get a Result:
{
"prediction": [
[
{
"class": "n02124075 Egyptian cat",
"probability": 0.8515276312828064
},
… (other lower probability predictions) …
}
The reason I chose Apache’s Solution here is because after my cursory
browsing research that seemed like the most mature option with decent amount
of features.
Model Archive:
It offers a feature to archive the model into a common format/representation
which allows it to support Models from various Deep Learning Frameworks.

Source:
- Article from a couple of years ago
- TensorFlow Serving
- Clipper
- Model Server for Apache MXNet
- DeepDetect
- TensorRT
- Model Serving in PyTorch
- AutoGluon
- TVM
My Podcast!
If you like topics such as this then please consider subscribing to my podcast. I talk to some of the stalwarts in tech and ask them what their favorite productivity hacks are:
Available on iTunes Podcast
Visit Void Star Podcast’s page on iTunes Podcast Portal. Please Click ‘Subscribe’, leave a comment.
