
In this post, we will see how ridiculously easy it is to parallel sort with no
external libraries, no special constructs, no delicate CUDA programming -
basically, no more hairfall! They support other algorithms such as
std::transform std::transform_reduce which I have not played with yet.
This requires NVidia’s nvcc compiler which comes as a part of their HPC SDK release 1
In an earlier post, I had briefly
discussed the rude shock I encountered when trying Parallel execution
policies. However, at the time my conclusion was only MSVC’s implementation
had picked up the tab on Parallel STL Algorithms. Turns out that there’s a
giant, NVidia who has some skin in this game. Some time last year, they released
their implementation of the stdpar in standard C++ via the latest nvcc
compiler toolchain.
I finally got around to trying this out so I wanted to share my initial observations.
- Hardware: EC2 p3.8x large
- OS: Ubuntu 20.04
- Software: NVCC Compiler
$ nvc++ --version
nvc++ 21.7-0 64-bit target on x86-64 Linux -tp haswell
NVIDIA Compilers and Tools
Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
$
C++ defines various execution policies for the compiler implementations to implement. The policies are:
std::execution::seq: Sequential execution. No parallelism is allowed.std::execution::unseq: Vectorized execution on the calling thread (this execution policy was added in C++20).std::execution::par: Parallel execution on one or more threads.std::execution::par_unseq: Parallel execution on one or more threads, with each thread possibly vectorized.
Since I haven’t switched to C++20 yet let’s use the three execution policies available.
The vector is initialized with the following code:
std::for_each(vals.begin(), vals.end(), [](auto& e){ e = std::rand(); });
Sequential
std::sort(std::execution::seq, vals.begin(), vals.end());
Parallel
std::sort(std::execution::par, vals.begin(), vals.end());
Parallel with Vectors
My guess is that this option uses AVX512-like instructions on CPU or intelligently
std::sort(std::execution::par_unseq, vals.begin(), vals.end());
Measuring Times
For instance, to measure the time taken to sort the input with sequential execution I did:
auto tic = std::chrono::steady_clock::now();
std::sort(std::execution::seq, vals.begin(), vals.end());
auto toc = std::chrono::steady_clock::now();
time_diff(tic, toc, "seq", n_);
The usual quick calc to print time:
auto time_diff = [](auto& s, auto& e, auto conf, int n) {
float duration = std::chrono::duration_cast<std::chrono::microseconds>
(e - s).count();
std::cout << n << "," << duration << "," << conf << "," << "multicore/gpu??" << std::endl;
};
Compile Time Options
nvc++ allows us to compile the program for heterogeneous systems:
nvc++ -stdpar=gpu stdpar.cc -o sortesh_gpu
or homogeneous multicore systems as show below:
nvc++ -stdpar=multicore stdpar.cc -o sortesh_multicore
To top it I started looking at the Flamegraphs to make sure the workload was indeed being offloaded to GPU as promised (since the p3.8x large is a huge machine and it becomes hard to really tell the perf between sorting a 100 Billion numbers on modern CPUs vs a bulky set of GPUs.

Then I looked into the off-CPU stacks with:
bpftrace -e 'tracepoint:sched:sched_switch { @[kstack] = count(); }'
After this the Flamegraphs themselves were created with:
./flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us < gpu_sort_bpftrace.sc > gpu_offcpu_bpftrace.svg

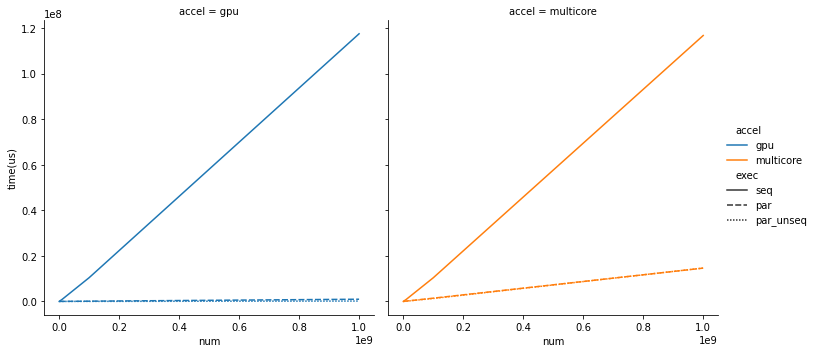
Conclusion
stdpar implementation in NVidia’s nvc++ provides a nice construct for
standard C++ implementation. The speedups are pretty impressive compared to the
vanilla sequential implementation.
References:
-
- https://developer.nvidia.com/blog/accelerating-standard-c-with-gpus-using-stdpar/
My Podcast!
If you like topics such as this then please consider subscribing to my podcast. I talk to some of the stalwarts in tech and ask them what their favorite productivity hacks are:
Available on iTunes Podcast
Visit Void Star Podcast’s page on iTunes Podcast Portal. Please Click ‘Subscribe’, leave a comment.
